IN UIRE
UIRE
A Benchmark for Natural World Image Retrieval
Edward Vendrow*1, Omiros Pantazis*2, Alexander Shepard3, Gabriel Brostow2, Kate E. Jones2, Oisin Mac Aodha†4, Sara Beery†1, Grant Van Horn†5
1Massachusetts Institute of Technology 2University College London 3iNaturalist 4University of Edinburgh 5University of Massachusetts, Amherst *, † indicates equal contribution & equal advising
Expert-level multi-modal models require expert-level benchmarks.
We introduce 🔍 INQUIRE, a text-to-image retrieval benchmark of 250 challenging ecological queries that are comprehensively labeled over a new 5 million image subset of iNaturalist (iNat24). We hope that 🔍 INQUIRE will encourage the community to build next-generation image retrieval methods toward the goal of helping accelerate and automate scientific discovery.
We introduce 🔍 INQUIRE, a text-to-image retrieval benchmark of 250 challenging ecological queries that are comprehensively labeled over a new 5 million image subset of iNaturalist (iNat24). We hope that 🔍 INQUIRE will encourage the community to build next-generation image retrieval methods toward the goal of helping accelerate and automate scientific discovery.
A hermit crab using plastic trash as its shell
Distal rynchokinesis
California condor tagged with a green “26”
Everted osmeterium
An ornamented bowerbird nest
A nest brood parasitized by a cowbird
A sick cassava plant
Tamandua back-brooding its young
A hermit crab using plastic trash as its shell
Want to search own queries? Try the live demo →.
Queries
The 250 queries contained within INQUIRE come from discussions and interviews with a range of experts including ecologists, biologists, ornithologists, entomologists, oceanographers, and forestry experts.
We exhaustively labeled these queries, finding over 33k relevant images (from 1 to 1k+ image matches per query) in iNat24.
Our queries cover a range of topics and a organism taxonomies:
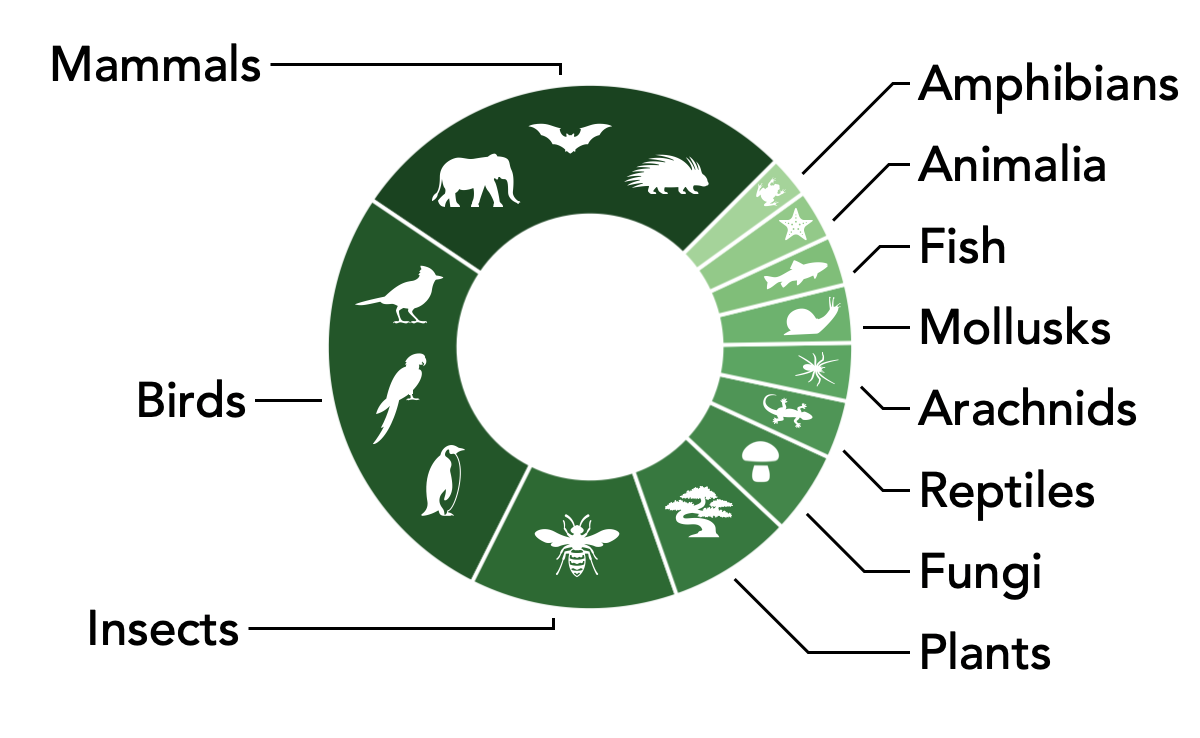
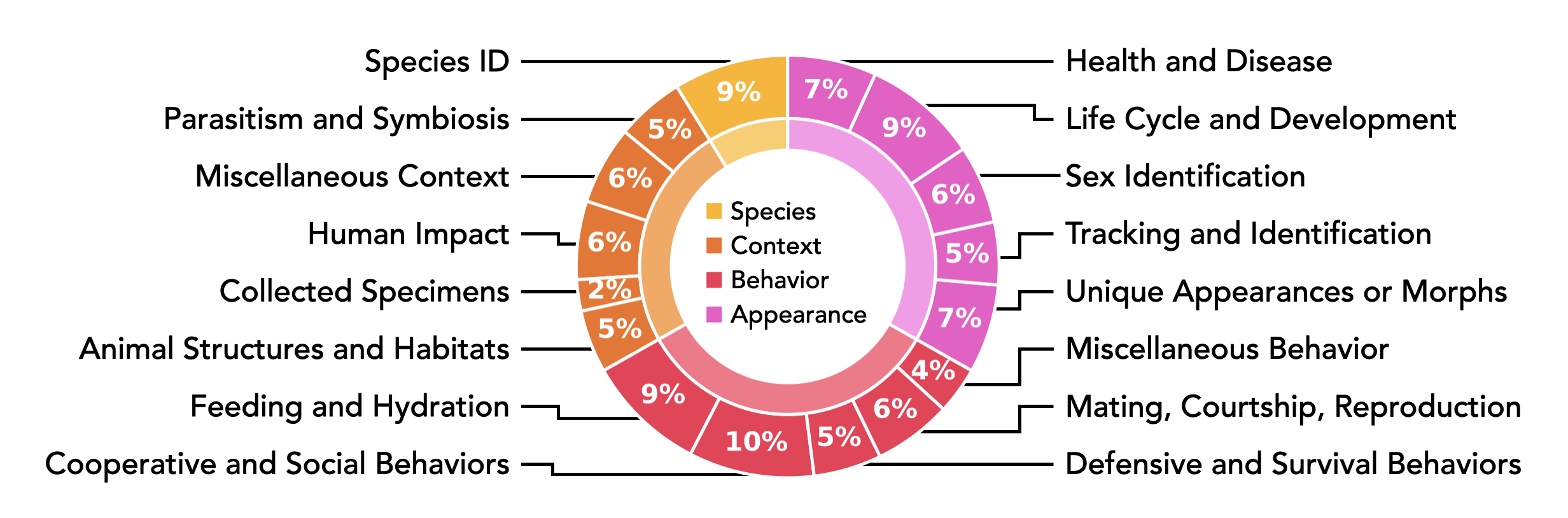
Tasks
INQUIRE includes two key tasks:
INQUIRE-Fullrank: Retrieving images from the full 5M image dataset
This is the full-dataset retrieval task, starting from all 5 million images of iNat24. We evaluate one-stage retrieval, using similarity search with CLIP-style models, and two-stage retrieval, where after the initial retrieval, a large multi-modal model is used to rerank the images.
This is the full-dataset retrieval task, starting from all 5 million images of iNat24. We evaluate one-stage retrieval, using similarity search with CLIP-style models, and two-stage retrieval, where after the initial retrieval, a large multi-modal model is used to rerank the images.
INQUIRE-Rerank: Reranking task for refining a fixed set of top-100 CLIP retrievals.
INQUIRE-Rerank evaluates reranking performance by fixing an initial retrieval of 100 images for each query (from OpenClip's CLIP ViT-H-14-378). For each query (e.g. A mongoose standing upright alert), your task is to re-order the 100 images so that more of the relevant images are at the "top" of the reranked order.
INQUIRE-Rerank evaluates reranking performance by fixing an initial retrieval of 100 images for each query (from OpenClip's CLIP ViT-H-14-378). For each query (e.g. A mongoose standing upright alert), your task is to re-order the 100 images so that more of the relevant images are at the "top" of the reranked order.
We recommend starting with INQUIRE-Rerank as it is much smaller and easier to work with.
INQUIRE-Rerank is available on 🤗 HuggingFace!
INQUIRE-Rerank is available on 🤗 HuggingFace!

INQUIRE Leaderboards
We evaluate current multimodal models on INQUIRE, both on the Fullrank and Rerank task. Evaluations are conducted in a zero-shot fashion, with no additional prompt-turning or in-context demonstrations. Results are reported in AP@50, the average precision among the top 50 retrieved images.
INQUIRE-Fullrank Leaderboard
This leaderboard shows full dataset retrieval performance, starting from all 5 million images in iNat24.
Two Stage Retrieval
One Stage Retrieval CLIP/Embedding Model
| Method | Size | Overall | Appearance | Behavior | Context | Species |
|---|---|---|---|---|---|---|
| CLIP ViT-H/14-378 (DFN) Top 100 → GPT-4o | - | 47.1 | 36.6 | 49.7 | 51.9 | 59.4 |
| CLIP ViT-H/14-378 (DFN) Top 100 → VILA1.5-40B | - | 42.1 | 32.5 | 44.7 | 46.7 | 52.4 |
| CLIP ViT-H/14-378 (DFN) Top 100 → GPT-4-Turbo (20240409) | - | 38.8 | 29.7 | 40.0 | 42.2 | 54.7 |
| CLIP ViT-H/14-378 (DFN) Top 100 → PaliGemma-3B-mix-448 | - | 37.7 | 27.2 | 41.2 | 41.7 | 48.6 |
| CLIP ViT-H/14-378 (DFN) Top 100 → LLaVA-v1.6-34B | - | 37.4 | 28.0 | 39.0 | 41.8 | 50.8 |
| CLIP ViT-H/14-378 (DFN) | 987M | 35.6 | 25.7 | 38.7 | 36.5 | 52.7 |
| SigLIP SO400m-14-384 | 878M | 34.9 | 30.5 | 35.7 | 36.0 | 42.6 |
| SigLIP ViT-L/16-384 | 652M | 31.6 | 24.1 | 33.0 | 33.8 | 44.5 |
| CLIP ViT-L/14 (DFN) | 428M | 24.6 | 18.4 | 24.0 | 26.3 | 40.9 |
| CLIP ViT-B/16 (DFN) | 150M | 16.2 | 12.0 | 16.8 | 15.7 | 28.3 |
| CLIP ViT-L/14 (OpenAI) | 428M | 15.8 | 14.9 | 15.3 | 14.3 | 23.6 |
| CLIP RN50x16 (OpenAI) | 291M | 14.3 | 10.4 | 15.8 | 13.3 | 23.3 |
| CLIP ViT-B/16 (OpenAI) | 150M | 11.4 | 9.8 | 10.6 | 11.2 | 19.0 |
| CLIP ViT-B/32 (OpenAI) | 110M | 8.2 | 5.8 | 7.6 | 8.9 | 16.1 |
| CLIP RN50 (OpenAI) | 102M | 7.6 | 5.7 | 7.3 | 7.9 | 13.8 |
| WildCLIP-t1 | 150M | 7.5 | 5.2 | 8.0 | 7.0 | 13.2 |
| WildCLIP-t1t7-lwf | 150M | 7.3 | 6.5 | 6.8 | 6.4 | 13.1 |
| BioCLIP | 150M | 3.6 | 2.3 | 0.5 | 2.2 | 21.1 |
| Random | - | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
INQUIRE-Rerank Leaderboard
This leaderboard shows reranking performance, starting from a fixed set of 100 images per query.
Proprietary LMM
Open Source LMM
Open Source CLIP/Embedding Model
| Method | Size | Overall | Appearance | Behavior | Context | Species |
|---|---|---|---|---|---|---|
| GPT-4o | - | 62.4 | 59.7 | 61.9 | 70.6 | 42.4 |
| VILA1.5-40b | 40B | 54.3 | 50.4 | 55.1 | 61.9 | 36.0 |
| SigLIP SO400m-14-384 | 878M | 51.5 | 51.8 | 51.7 | 53.4 | 38.8 |
| GPT-4-Turbo (20240409) | - | 48.9 | 43.7 | 49.6 | 56.6 | 39.7 |
| PaliGemma-3b-mix-448 | 3B | 48.9 | 44.1 | 51.6 | 53.8 | 35.3 |
| LLaVA-v1.6-34b | 34B | 48.3 | 43.7 | 48.7 | 56.4 | 34.7 |
| SigLIP ViT-L/16-384 | 652M | 47.5 | 42.8 | 50.2 | 52.1 | 34.7 |
| VILA1.5-13B | 13B | 46.3 | 40.2 | 46.5 | 56.8 | 32.7 |
| CLIP ViT-H/14-378 (DFN) | 987M | 44.6 | 38.8 | 50.1 | 47.4 | 28.6 |
| InstructBLIP-FLAN-T5-XXL | 12B | 44.3 | 38.7 | 45.9 | 50.7 | 37.2 |
| LLaVA-v1.6-mistral-7b | 7B | 43.1 | 39.0 | 42.7 | 51.5 | 31.7 |
| LLaVA-1.5-13b | 13B | 43.0 | 37.7 | 45.1 | 48.9 | 32.7 |
| BLIP-2-FLAN-T5-XXL | 12B | 40.5 | 32.8 | 43.4 | 47.9 | 32.4 |
| CLIP ViT-L/14 (DFN) | 428M | 39.1 | 34.9 | 40.7 | 43.3 | 33.4 |
| CLIP ViT-L/14 (OpenAI) | 428M | 37.8 | 35.1 | 37.9 | 41.4 | 37.6 |
| CLIP RN50x16 (OpenAI) | 291M | 36.2 | 32.7 | 36.1 | 40.5 | 39.8 |
| CLIP ViT-B/16 (DFN) | 150M | 33.7 | 29.4 | 35.4 | 37.2 | 31.5 |
| CLIP ViT-B/16 (OpenAI) | 150M | 33.5 | 30.8 | 32.9 | 37.2 | 37.1 |
| WildCLIP-t1 | 150M | 31.6 | 28.2 | 31.0 | 36.5 | 34.3 |
| WildCLIP-t1t7-lwf | 150M | 31.5 | 29.0 | 30.5 | 35.2 | 37.4 |
| CLIP ViT-B/32 (OpenAI) | 151M | 31.3 | 26.9 | 30.4 | 37.3 | 37.0 |
| CLIP RN50 (OpenAI) | 102M | 31.2 | 28.8 | 30.3 | 35.0 | 35.2 |
| BioCLIP | 150M | 28.9 | 27.4 | 27.2 | 30.8 | 41.1 |
| Random | - | 23.0 | - | - | - | - |
Data
INQUIRE-Rerank
This includes 200 queries and 20k images (100 images per query).
The metadata (the list of queries and the list of images) is hosted on ourGithub repo.
Since this task only requires the 20k images, we also provide the entire INQUIRE-Rerank dataset and images on 🤗 HuggingFace! (We recommend you start here)
INQUIRE-Fullrank
This includes 33k relevant images from 250 queries. The images that this benchmark uses are the iNat24 dataset.
The dataset is hosted on ourGithub repo.
iNat2024
The iNaturalist 2024 dataset contains 5 million images from 10k species.
Instructions to download this full dataset are available on Githubhere.
Citation
If you found INQUIRE useful, please consider citing out paper:
@article{vendrow2024inquire,
title={INQUIRE: A Natural World Text-to-Image Retrieval Benchmark},
author={Vendrow, Edward and Pantazis, Omiros and Shepard, Alexander and Brostow, Gabriel and Jones, Kate E and Mac Aodha, Oisin and Beery, Sara and Van Horn, Grant},
journal={NeurIPS},
year={2024},
}